What is it?
The custom link detection function is designed for publishers that want an automated way to make unique URLs from text in their publications such as order numbers, product codes, page numbers, etc.
This could be a real help if you have an index in your publication and have many page numbers to link up but they are simply text on the page within the PDF. Or if your catalogue has lots of items that you want to link to the store or add them to the shopping cart from the publication.
The Basic Idea
Detect text and place part or all of it in a URL for a server script, html page, etc.
How do we do this?
Before you import your PDFs we need to set up the detection. So open 3D Issue and go to Options>Advanced>Custom Link Detection
This will open a window that looks like this:
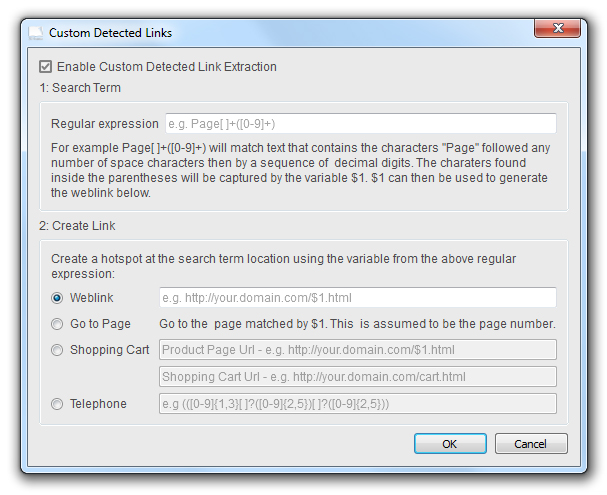
To detect the text we use a concept known as regular expressions (regex). These are essentially sets of characters that are used to identify patterns in text.
The basic syntax of regular expressions remains the same no matter where you use it. If you have a scripting or programming background you will probably already know what to do.
After we detect the text we will most likely need to do something with it!
3D Issue Offers three ways using the detected text – Linking to another page in your document, linking to an external page with a unique URL (based on the text you have detected) via the Weblink or Shopping Cart functions and Creating a custom Telephone link.
Detecting text
We’ll start off with a basic example of how we detect some text. Say we want to detect 123
We would simply open the custom link detection wizard from the Options menu of the software and enter 123 into the regex box. This will then detect all instances of “123” in the document. The same would apply to normal text, just type it in.
If you wanted to have a space in between each Number or Word you would insert [ ]
– that’s “bracket space bracket”
The regex for this would look like: 1[ ]2[ ]3
If there was more than one space you could simply put a “+” after the end bracket to signify that there was more than one space e.g. 1[ ]+2[ ]+3
Or if there was more than one “3” it would be 1[ ]2[ ]3+
What if I want to detect any number?
You can detect a single number (no matter which) by using [0-9]
If it was any 3 digit number you would use [0-9][0-9][0-9]
Or if it was a number of any size [0-9]+
Detecting any letter
Detecting letters is similar to detecting numbers.
To detect any letter you would use [a-zA-Z]
Any lower case letter would be: [a-z] or upper case letter would be: [A-Z]
Multiple numbers or letters
To text multiples of any detected character or string simply place “+” after it.
E.g. [0-9]+ or [a-zA-Z]+
Armed with that
If we wanted to detect a product code on a page – say the product was always going to be similar to:
PA12345
So PA will always be in front and there will always be 5 numbers behind it.
The regex would be PA[0-9] [0-9] [0-9] [0-9] [0-9]
Say if you wished to detect something similar to this: PA12345x (where x is a lowercase letter that might change)
You could simply use PA[0-9]+[a-z]
Using what is detected!
To use all or part of the detected text in the URL that is created we use parenthesis “( )” to capture the information. So for our example above we only want the numbers and the ending letter.
So we would wrap that section in parenthesis: PA([0-9]+[a-z])
The captured text is then stored in a variable called $1
This variable can be placed as part of your URL to signify where the captured data will be placed. For example if we want to post the product number to a php script we could use a url similar to:
http://your-domain.com/scripts/orderscript.php?number=$1
The $1 would get replaced in the final URL with the detected text so it would end up being:
http://your-domain.com/scripts/orderscript.php?number=12345x
Finally
Import your PDFs!
When you import your PDFs into 3D Issue you should see hotspots created around the various links and detected items in the publication. Just click on them and select properties if you want to check what they are linking to or if you want to add a link of custom text to.
Some points
- If you want to detect more than one type of link you can do this as long as they are on separate pages.
Import one page with the link detection enabled.
Change the regex to find a different link
Import the next set of PDFs and then arrange them as needed. - The detection will not work if words or text you are detecting are separated by a table – this can’t be detected as text.
- There are more complex sets of regex and syntax that can be used however you should avoid any that use parenthesis. There are many tutorials and tools available online for regex. Unfortunately we cannot link them all here but they’re not hard to find. That said, basic text and numerical detection should be enough for most* publications.
- Because of the nature of PDFs and the characters’ that can be embedded into the text wild-card detection should be avoided as it will be unreliable at best.
You can always send us a message and we’ll be glad to provide assistance or even generate the required regex for your PDF.